One of the primary objectives of artificial intelligence research is modeling intelligent agents with human-level language capabilities that can participate in dialog to support task-oriented collaboration and engage in life-long learning. The Language Endowed Intelligent Agents (LEIA) lab at Rensselaer is working on the holistic development of human-level, language endowed, explainable intelligent agent systems. Language processing in LEIAs is developed according to Ontological Semantics – a human-inspired theory of language understanding – and covers both Natural Language Understanding (NLU) and Natural Language Generation (NLG). The research paradigm involves developing agents through the lens of content-centric computational cognitive modeling which is a knowledge-based approach to developing intelligent systems that incorporates linguistics, artificial intelligence, psychology, and philosophy (Sun, 2008; Nirenburg at al., 2020). Content-centric computational cognitive modeling is inspired by how we believe people learn, understand, and make decisions, but does not claim to replicate the human mind in a machine.
Recent successes of large statistical language models such as GPT-3 and Switch-C have re-ignited widespread interest in natural language processing (NLP) systems – particularly in natural language generation – with the promise of delivering generated samples that feel close to human quality and coherence (Brown, 2020; Fedus, 2021). While these models certainly do generate language that feels natural to humans, three core issues remain which limit their utility:
Neural systems have no way of “knowing” what they are generating, resulting in errors such as overly repetitive text, word-modeling failures (e.g., writing about “fires happening under water”), and erratic topic switching (Radford, 2019).
Neural dialog models struggle to be contextually relevant since their primary source of context is typically just a dialog history.
Neural models cannot explain their decisions or behavior, leading to distrust of artificial intelligence (AI) systems (Xu, 2019) – though progress has been made on interpretability.
Further, Bender et al. (2021) argue in the critical paper “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” that there are additional environmental and ethical considerations to contend with when designing, training, and deploying large language models. A subsequent paper by Bommasani et al. (2021), “On the Opportunities and Risks of Foundation Models”, raises yet another set of concerns: “despite the impending wide-spread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties.” They believe, and I agree, that “much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally socio-technical nature.”
In contrast to the methods used in end-to-end neural language models OntoGen approaches language generation using the notion of constructions. Constructions are conventionalized, formal pairings of form and meaning that scaffold the knowledge of a language by connecting the syntactic and semantic components of a piece of the language (McShane et al., 2021). They have long been a popular topic of study in linguistics, but have become a central topic in construction grammar, a cluster of theories known as constructionist approaches whose goal is to explain humans’ knowledge of language (Hoffmann & Trousdale, 2013). Under the scope of construction grammar, much of the focus is on analyzing sentences by listing the constructions that make it up and conveying the semantics of those constructions using natural language paraphrases. OntoGen, on the other hand, models construction usage in natural language generation as processes which select and combine relevant constructions and lexical senses into sentences.

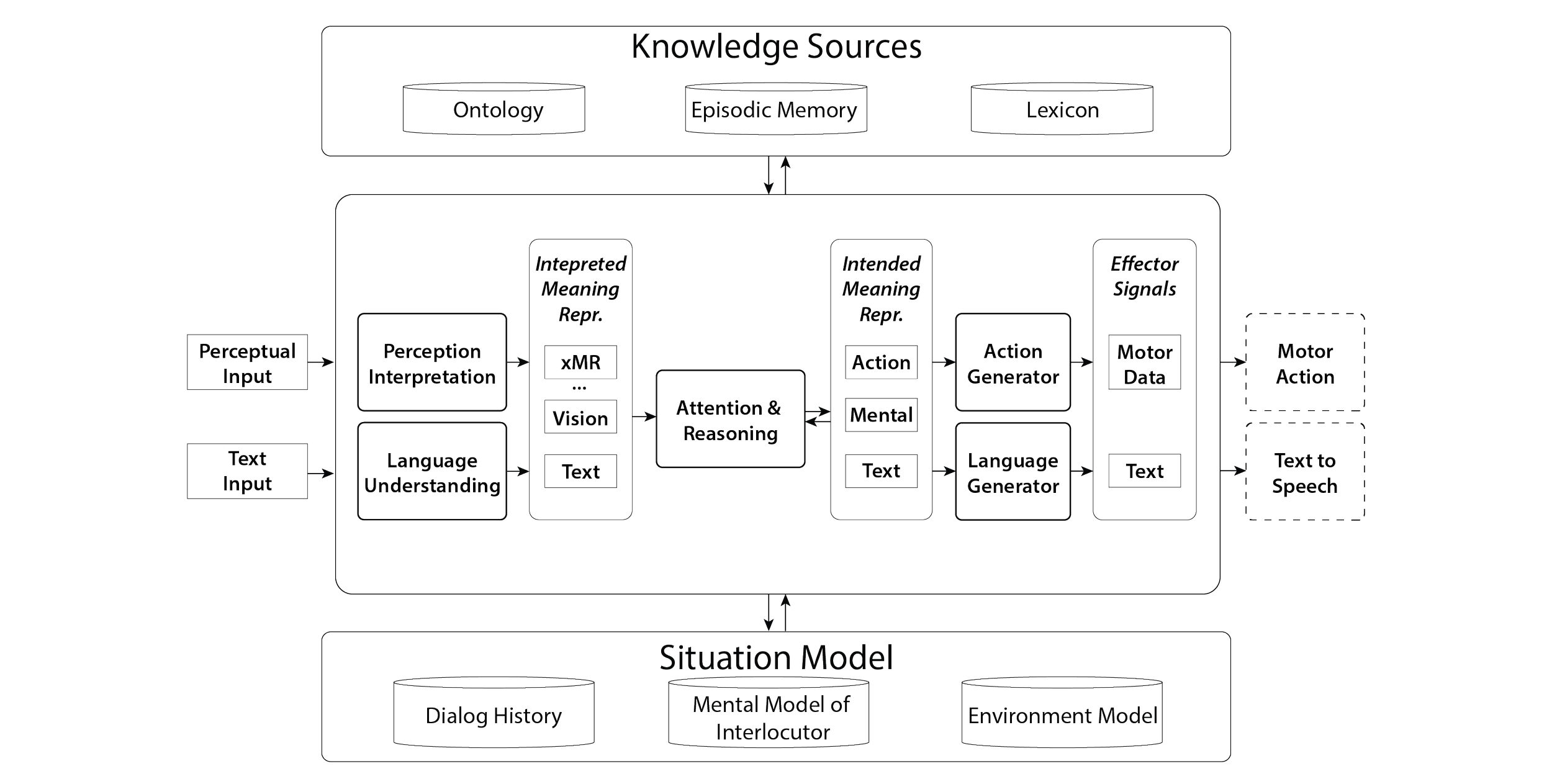
OntoGen relies on a variety of knowledge resources in order to function. (1) A construction-rich English lexicon containing around 30,000 linked syntactic and semantic descriptions of lexemes, which allows the generator to select appropriate words or phrases to render a particular meaning. (2) A property-rich ontology, or world model, containing around 9,000 concepts that forms the basis of agent knowledge and grounds all semantic descriptions in the lexicon and memory. (3) A dynamically populated episodic memory which forms the foundation for the situation model and interaction history.
NLG systems are comprised of two main tasks: determining what to say and then figuring out how to say it (Reiter, 2000). To generate a sentence, an NLG system must first determine what to say by creating a meaning representation for the intended meaning. Once the meaning representation is created, the NLG system can select and order the words to render the intended meaning. Compare this to neural approaches which simply take an input sentence or dialog history and choose the subsequent words according to the probability of those words appearing next. Machine learning methods don’t determine what to say or how to say it, they just say it. Research on the OntoGen NLG system is focused on what happens after an agent has decided what to say.
There are four primary phases in OntoGen. (1) The Lexical Selection phase is responsible for selecting the appropriate words to populate the corresponding GMR Frame and can be performed using one of three matching algorithms: exact matching, parent matching, and fuzzy matching. Exact matching requires the concept contained in the semantic description of a construction/lexeme to be exactly the concept indicated by the respective TMR frame. Parent matching allows the concept to be relaxable to the ontological parent of the concept (vertically up the ontological graph a specified number of levels). Fuzzy matching is the most complex, allowing the construction/lexeme to match the frame both vertically and horizontally in the graph, and requires additional knowledge and meaning procedures.

(2) The Lexical Compilation phase is responsible for combining relevant words, ordering them according to their collective syntactic descriptions, filtering out inadequate candidates, and returning a PhraseStructure. A PhraseStructure is a set of ontologically grounded words that satisfies the meaning represented in the GMR for each frame. PhraseStructures are then passed on to (3) the SimpleNLG Realization phase, which was facilitated by the porting of the source code for native OntoGen integration. This phase is responsible for turning the PhraseStructures into English sentences, otherwise known as morphological and surface realization (Reiter & Gatt, 2009). SimpleNLG has outlined some of its own limitations in grammatical coverage, which will be present in realized sentences generated by OntoGen. Realized candidate sentences are then ranked in (4) the Ranking and Selection phase to aid the system in selecting the output sentence. This involves a combination of knowledge-based heuristics and a fine-tuned transformer model to score each candidate in accordance with a dialog history as well as relevance and semantic scores. Using machine learning methods to aid in candidate selection is useful here because of the broad vocabulary coverage of statistical language models and their inherent encapsulation of the distributional semantics of dialog structures in a language.
The explanation and visualization system for OntoGen, OntoOptics, is a publish/subscribe system that listens to and records changes to OntoAgent memory objects. It’s built to integrate into the OntoAgent dashboard system called DEKADE and can display the state of underlying agent memory. As part of OntoOptics, an evaluation suite to measure congruence between the intended GMR and the resulting utterance with input from the situation model is being developed to evaluate system performance as well as inform the generation process in real-time.
One of the main advantages of neural methods over knowledge-based NLG methods is the speed of development due to the availability of surface-level data for training and fine-tuning. The availability of knowledge and data for knowledge-based methods is scarce and has historically required developers of such systems to hand-build knowledge resources from scratch. This is known as the knowledge acquisition bottleneck (Cullen & Bryman, 1998). LEIA knowledge resources are still far from sufficient for a fully domain-independent system but contain enough knowledge to form critical mass of knowledge from which an agent can bootstrap subsequent learning/knowledge acquisition. While machine learning based NLG systems may appear to have broader vocabulary coverage than knowledge-based systems, the latter have a much deeper semantic understanding of the vocabulary, leading to more accurate and controllable generation.
In addition to the difference in data consumption, the prevalent evaluation methods used for neural NLG systems are unsuitable for knowledge-based methods because they measure the accuracy of the model in predicting the next utterance. OntoGen cannot be evaluated in this way, as its goal is not to predict the next word or sentence given a dialog history, but rather to reason about the situation to dynamically generate a relevant utterance. The evaluation method must therefore measure the relevance of a generated utterance and its congruence with the TMR, situation model, and mental model of the interlocutor.
Recent developments have shown that it is unlikely that machine learning by itself will solve the hardest problems of AI, including deep language processing, making it absolutely necessary to integrate statistical and knowledge-based methods. Since the majority of researchers in the field primarily use neural methods, they naturally assume that knowledge-based methods will assist machine learning. We are taking the opposite approach, incorporating machine learning to aid in a primarily knowledge-based process. This work differs significantly from past work in that I am incorporating knowledge-based and statistical methods to generate natural language from knowledge structures as part of a larger cognitive system.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: can language models be too big? Conference on Fairness, Accountability, AndTrans- Parency (FAccT ’21). https://doi.org/10.1145/3442188.3445922
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., ... & Liang, P. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language models are few-shot learners. ArXiv.
Cullen, J., & Bryman, A. (1998). The knowledge acquisition bottleneck: time for reassessment? Expert Systems, 5(3), 216-225.
Ehud, R., & Dale, R. (2000). Building Natural Language Generation Systems. Cambridge University Press.
Fedus, W., Zoph, B., & Shazeer, N. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. ArXiv Preprint ArXiv:2101.03961.
Gatt, A., & Reiter, E. (2009). SimpleNLG: A realisation engine for practical applications. Proceedings of the 12th European Workshop on Natural Language Generation, ENLG 2009, March, 90–93.
Hoffmann, T., & Trousdale, G. (2013). The Oxford Handbook of Construction Grammar. Oxford University Press.
Leon, I. E. (2020). OntoGen: A Knowledge-Based Approach to Natural Language Generation (Issue July).
McShane, M., & Leon, I. E. (2021). Language Generation for Broad-Coverage, Explainable Cognitive Systems. Advances in Cognitive Systems, 1-17.
McShane, M., Jarrell, B., Fantry, G., Nirenburg, S., Beale, S., & Johnson, B. (2008). Revealing the conceptual substrate of biomedical cognitive models to the wider community. Studies in Health Technology and Informatics, 132, 281–286.
Nirenburg, S., Mcshane, M., & English, J. (2020). Content-Centric Computational Cognitive Modeling. Advances in Cognitive Systems, 1–6.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog, 1.
Sun, R. (2008). The Cambridge Handbook of Computational Psychology. Cambridge University Press.
Xu, F., Uszkoreit, H., Du, Y., Fan, W., Zhao, D., & Zhu, J. (2019). Explainable AI: A Brief Survey on History, Research Areas, Approaches and Challenges. CCF International Conference on Natural Language Processing and Chinese Computing, September, 563–574. https://doi.org/10.1007/978-3-030-32236-6_51